White Paper: The 2026 AI Inflection - Chapter 11: Build an Evals Management System Before You Scale
A 16-page white paper making the case that evaluation infrastructure is the prerequisite for scaling enterprise AI safely. Defines what an evals management system is, why it matters before production deployment, and how to build one that goes beyond benchmark scores.
Author / Lead
2026-03-24

Overview
You cannot govern what you cannot measure. Yet more than 60% of enterprise AI projects deploy without a structured evaluation framework. This white paper defines the four evaluation layers every AI system needs and shows how to build an evals management system before scaling, not after an incident.
Case Study
The Challenge
Most teams treat evaluation as a pre-launch checklist. Once in production, monitoring is often informal and incident-driven.
The Solution
Defined a four-layer evaluation architecture and a pipeline covering test design, automated execution, scoring, and longitudinal tracking.
Key Results
Functional, behavioral, safety, and regression
Evaluation Layers
Test design, execution, scoring, and tracking as continuous infrastructure
Pipeline
Evals gate every production release and catch drift before users are affected
Governance
60%+ of enterprise AI projects skip structured evaluation
Coverage Gap
Key Takeaways
16
Pages
4
Evaluation Layers
3
Pipeline Stages
60%+
AI Projects That Skip Structured Evals
View Document
Download or Open in New Tab to access the links to download or access the tools / templates or research materials within the document.




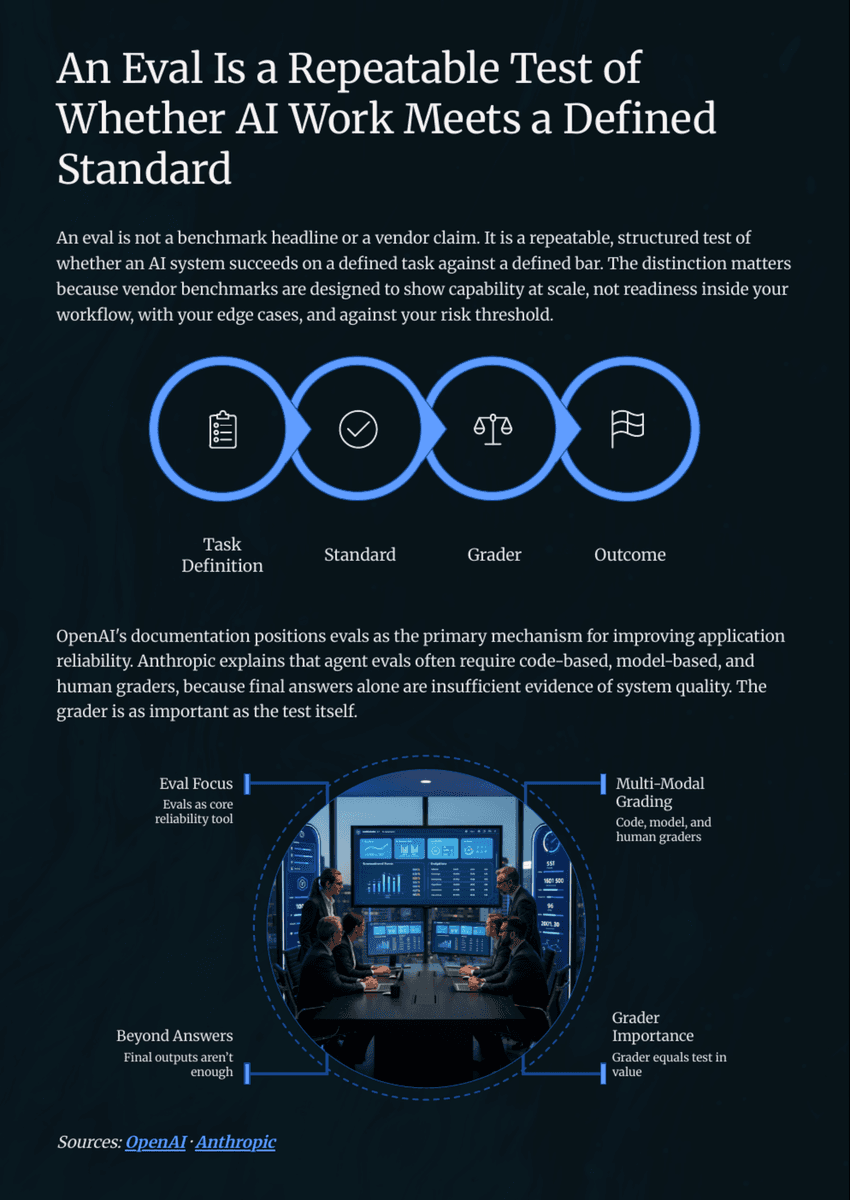


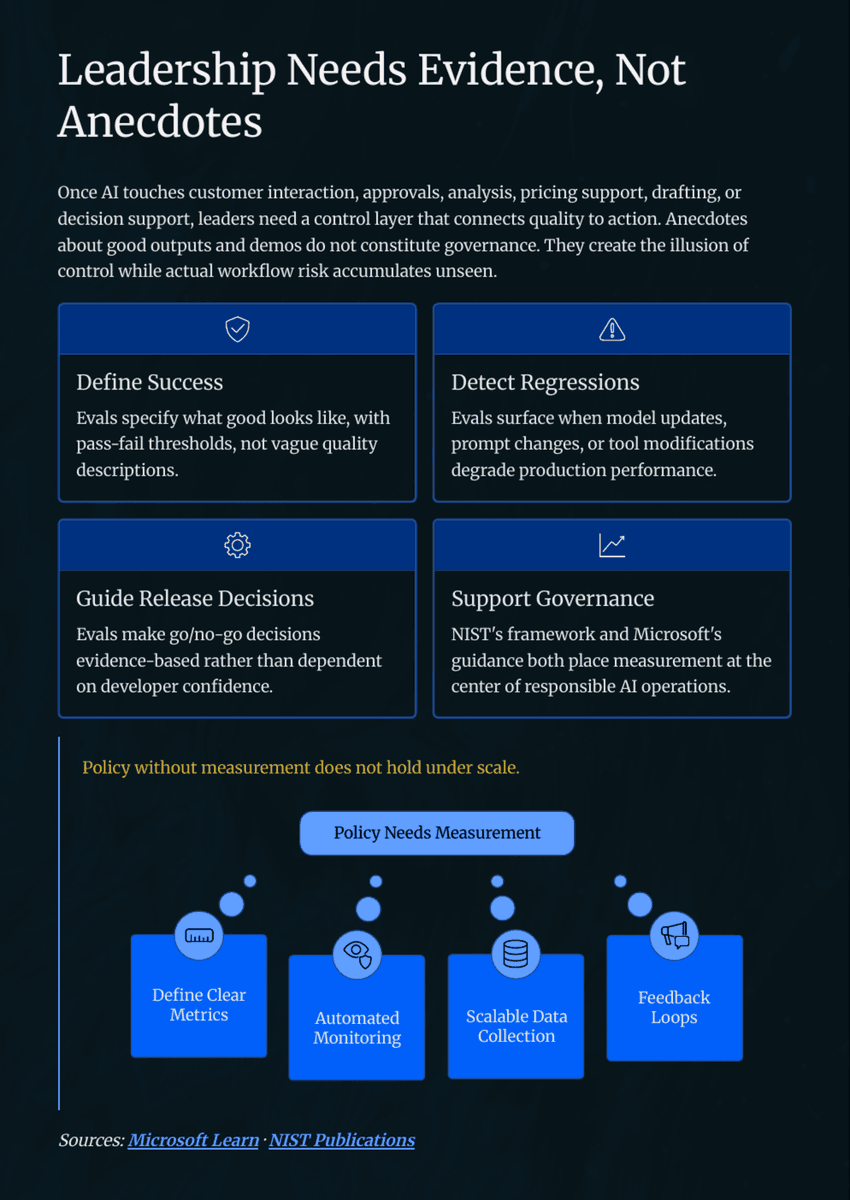




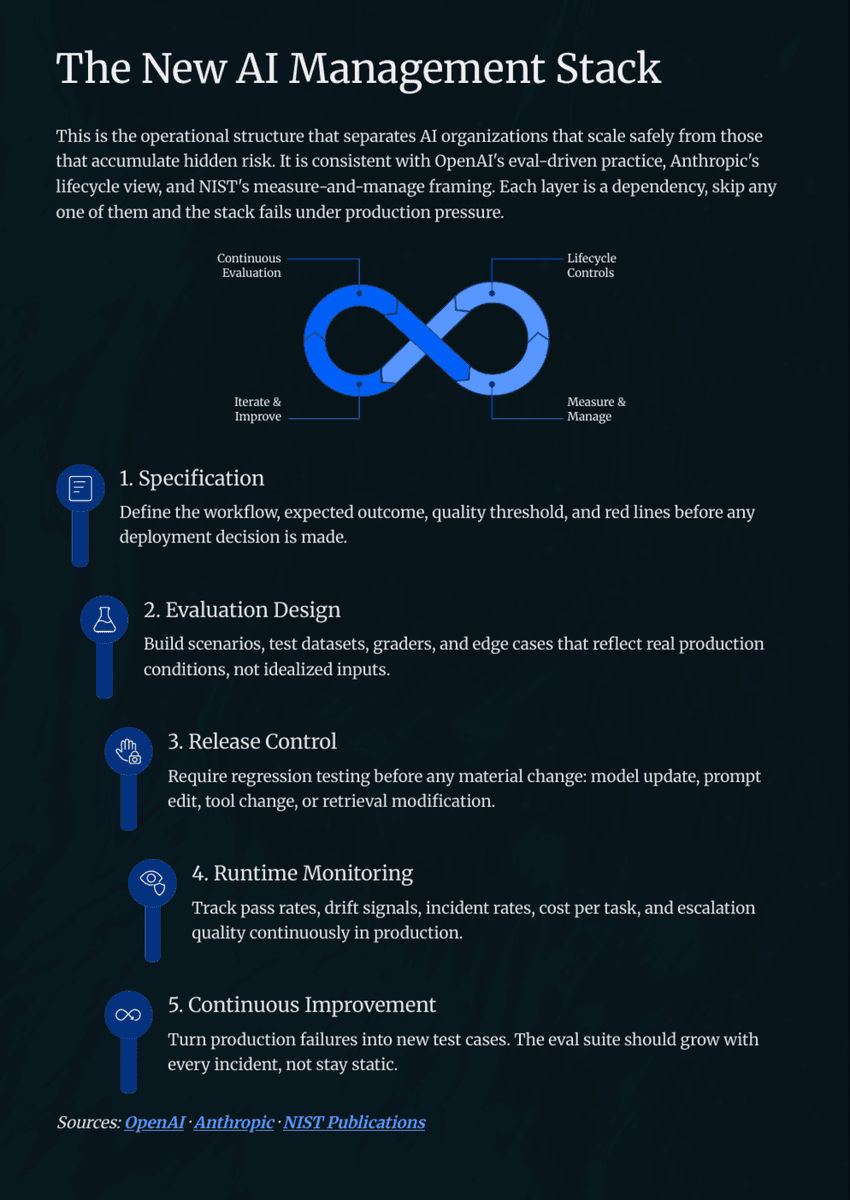
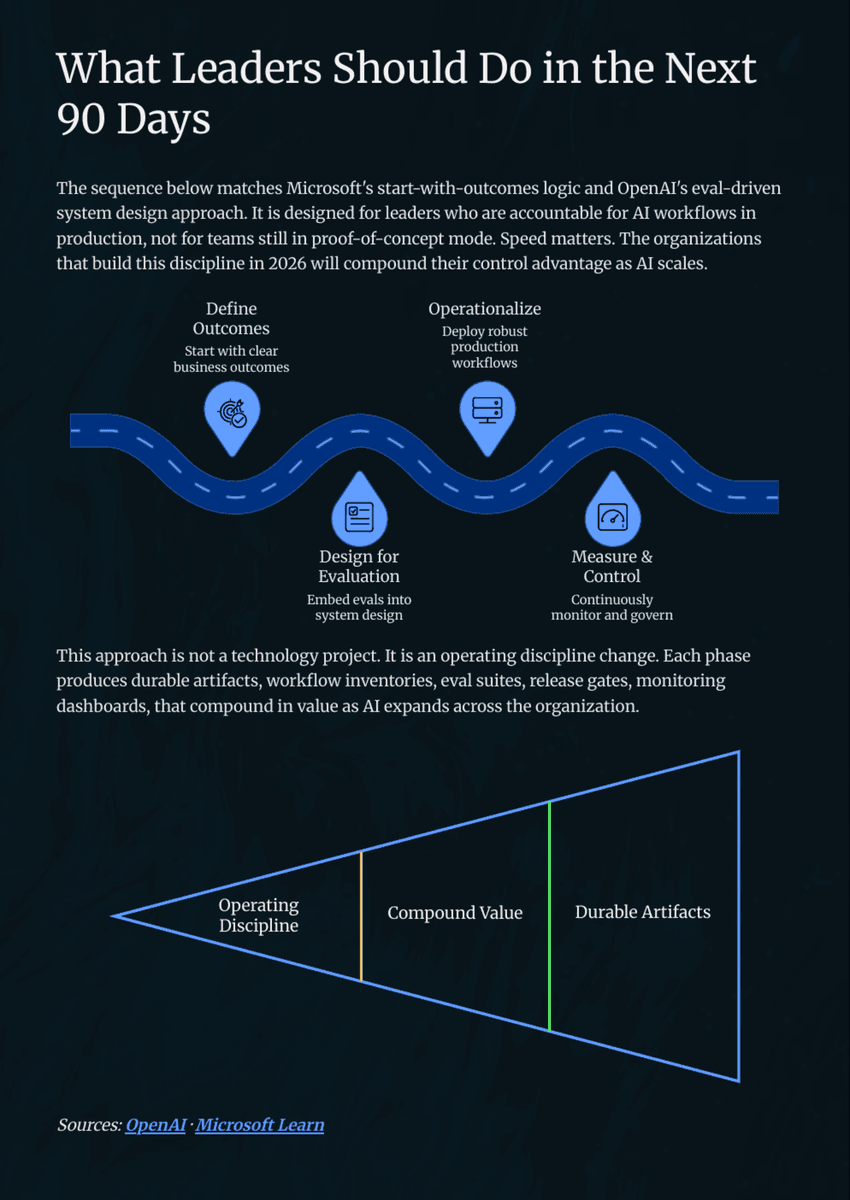


Responsibilities
- Authored the full white paper on evals management systems for enterprise AI
- Defined the four evaluation layers: functional, behavioral, safety, and regression
- Built the eval pipeline architecture covering test design, execution, scoring, and tracking
Outcomes
16
Pages
4
Evaluation Layers
3
Pipeline Stages
60%+
AI Projects That Skip Structured Evals


